Definição
Apresentação da evolução histórica dos bancos de dados, abordando as características dos sistemas de banco de dados (SBD) e a arquitetura dos sistemas de gerência de banco de dados (SGBD).
PROPÓSITO
Compreender a origem e as características dos SBDs, bem como suas funcionalidades, vantagens e desvantagens, além de conhecer a arquitetura dos SGBDs e os sistemas mais utilizados em bancos de dados.
OBJETIVOS
Módulo 1
Reconhecer o histórico dos bancos de dados e suas tecnologias
Módulo 2
Identificar as características dos sistemas de banco de dados (SBD)
Módulo 3
Descrever a arquitetura dos sistemas de gerência de banco de dados (SGBD)
INTRODUÇÃO
MÓDULO 1
Reconhecer o histórico dos bancos de dados e suas tecnologias
Definição de banco de dados
Você certamente já leu sobre o termo banco de dados em algum contexto técnico ou geral na mídia tradicional ou na internet.
Mas o que é um banco de dados?
O termo banco de dados, no sentido técnico, origina-se de database, do inglês, e o livro-texto de edição norte-americana mais adotado no mundo o define de maneira simples e direta: “banco de dados é uma coleção de dados relacionados” (ELMASRI; NAVATHE, 2019), em que dados são fatos conhecidos que podem ser registrados e possuem significado implícito.
Exemplo
Nome, data de nascimento, endereço e telefone são dados relacionados entre si, inerentes a uma pessoa conhecida em certo contexto. Antes de elaboramos mais essa definição, vamos relembrar um pouco da história dos bancos de dados.

O conceito de banco de dados como uma coleção de dados relacionados sempre existiu como componente central dos sistemas de informação. Estes, por sua vez, sempre existiram desde que a humanidade se organizou como sociedade. Segundo afirmam Melo, Silva e Tanaka (1998), o que tem mudado rapidamente ao longo da história é a tecnologia que permite a sua implementação e que se confunde com o próprio conceito de sistemas de informação.
Assim, antes da existência do computador, bancos de dados existiam sob a forma de registros físicos em papel, organizados em pastas dentro de armários, que formavam os arquivos dos sistemas de informação, operados manualmente pelos seus usuários. Será que ainda existem sistemas de informação desse tipo em pleno século XXI?
Evolução dos sistemas de informação em computador

Era do processamento de dados
Historicamente, o computador, inventado na década de 1940 ao fim da Segunda Guerra Mundial, era usado primordialmente como uma máquina para cálculos matemáticos complexos, a exemplo da máquina diferencial de Charles Babbage, do século XIX.
Charles Babbage
Charles Babbage (1791-1871) é um dos mais célebres ícones no mundo da computação. As suas notáveis contribuições para a área fizeram dele o pioneiro dos computadores. A Máquina Diferencial N. 1 foi a primeira calculadora automática a ser inventada e ainda é considerada uma peça única pela precisão que na época apresentava.
Fonte: Pplware.Logo se percebeu que, graças à arquitetura criada pelo seu inventor, John von Neumann, baseada em uma unidade central de processamento que armazena programas e dados, o computador também serve para o processamento de dados e não apenas para cálculos.

John von Neumann
John von Neumann (1903-1957) foi um matemático húngaro, naturalizado norte-americano, considerado o pai da Teoria dos Jogos. Seus interesses abrangiam lógica, assuntos militares, computação, economia, entre outros.

Essa utilidade do computador foi impulsionada com a invenção do disco magnético pela IBM, em 1957, que o denominou de Dispositivo de Armazenamento de Acesso Direto (DASD, do inglês Direct Acess Storage Device).
Fundamentalmente, o que esse dispositivo – atualmente conhecido como disco rígido e pela sigla HD (Hard Disk) – apresentou de novidade, à época, foi a capacidade de leitura de dados externos à unidade central de processamento de forma direta, sem a necessidade de leitura sequencial, como em fitas magnéticas.
Com o advento do armazenamento externo em disco rígido, nasceu a era do processamento de dados por computador.
Você já ouviu falar em Centro de Processamento de Dados (CPD), denominação que ainda persiste em organizações tradicionais?
Nessa era, os programas de aplicação, desenvolvidos em uma linguagem de programação (usualmente COBOL, em aplicações empresariais, ou Fortran, em aplicações científicas), manipulavam dados armazenados em arquivos hospedados em disco magnético, utilizados pelo sistema operacional e formando o que se denomina sistema de arquivos.

A figura a seguir mostra a evolução obtida ao possibilitar que os programas acessassem os dados externamente em arquivos no disco (configurando um avanço em relação aos programas que continham internamente os próprios dados) para execução em lotes (batch, em inglês), na fase inicial do uso do computador.
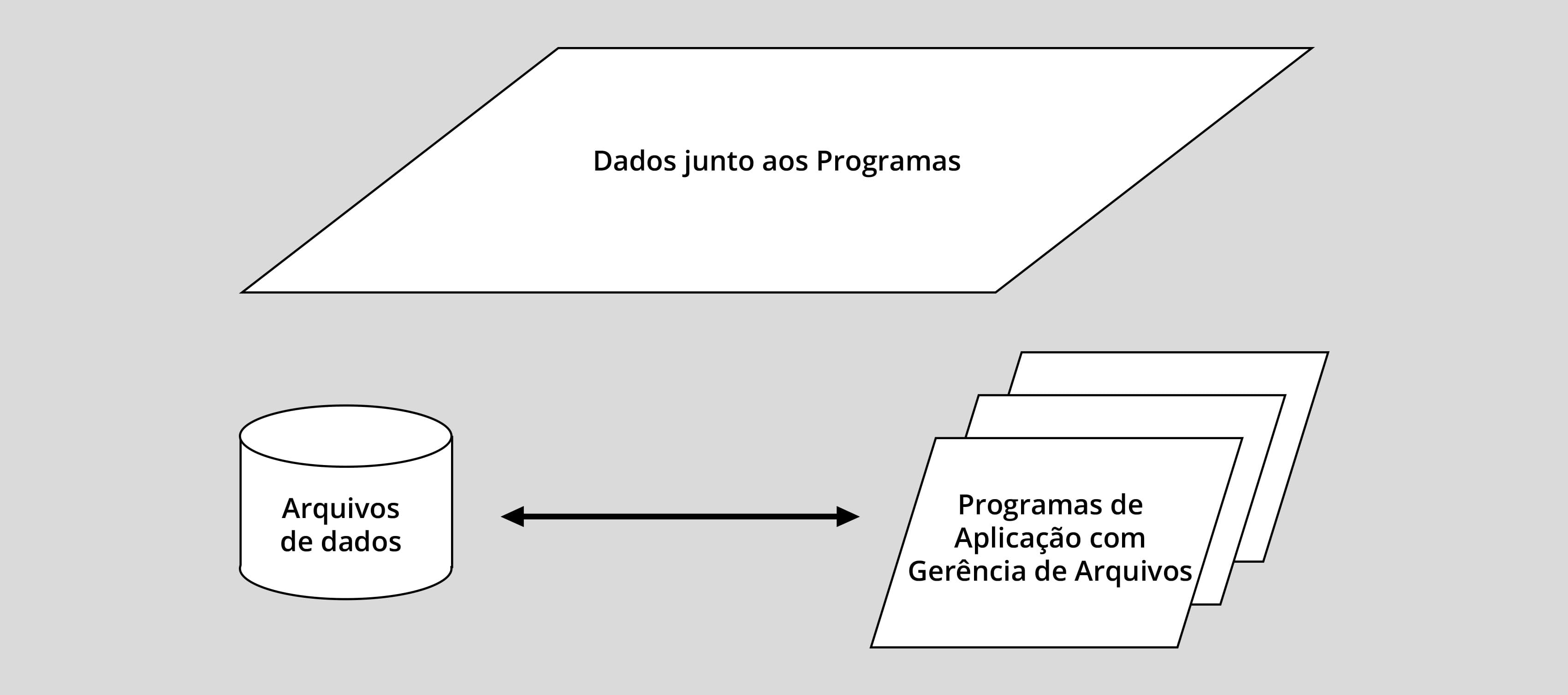
Esse modelo de processamento de dados com sistema de arquivos foi largamente utilizado no início do emprego do computador em sistemas de informação empresariais, após o advento do disco magnético, persistindo até os dias atuais, nos chamados sistemas legados. Exemplo disso, foi a maior demanda por programadores da linguagem COBOL durante a pandemia de COVID-19 para realizar manutenção em sistemas da Administração Pública do governo dos EUA.
Saiba mais
Para saber mais sobre o aumento da procura por programadores COBOL durante a pandemia de COVID-19, não deixe de verificar a indicação feita no Explore + ao fim deste tema.
Primórdios dos sistemas de banco de dados

Seguindo na história, o advento dos bancos de dados foi uma evolução natural dos sistemas de arquivos. Observe na figura anterior que os programas os quais manipulam os arquivos de dados, além de implementarem a lógica da aplicação, têm de conter um módulo para a gerência dos arquivos de dados. Esse módulo deve ser repetido em todos os programas que precisam acessar e manipular o mesmo arquivo de dados.

Por exemplo, o departamento de pessoal de uma organização mantém o arquivo com os dados dos empregados. Suponha que o departamento de produção também precise usar dados desse arquivo para alocar empregados em projetos. Nesse caso, os programas de aplicação que atendem aos dois departamentos deverão conter o mesmo módulo de gerência do arquivo de empregados, causando uma repetição de código de programação e dificultando a sua manutenção.

Assim, os sistemas de banco de dados (SBD) vieram para mitigar esse problema, a partir de 1960, tirando dos programas de aplicação a responsabilidade de gerenciar os arquivos de dados, tarefa que passou a ser delegada a um software intermediário, denominado de sistema de gerência de banco de dados (SGBD), como mostra a figura a seguir.
Essa propriedade dos sistemas de banco de dados é denominada de independência entre dados e programas, uma diferença primordial em relação aos sistemas de arquivos.
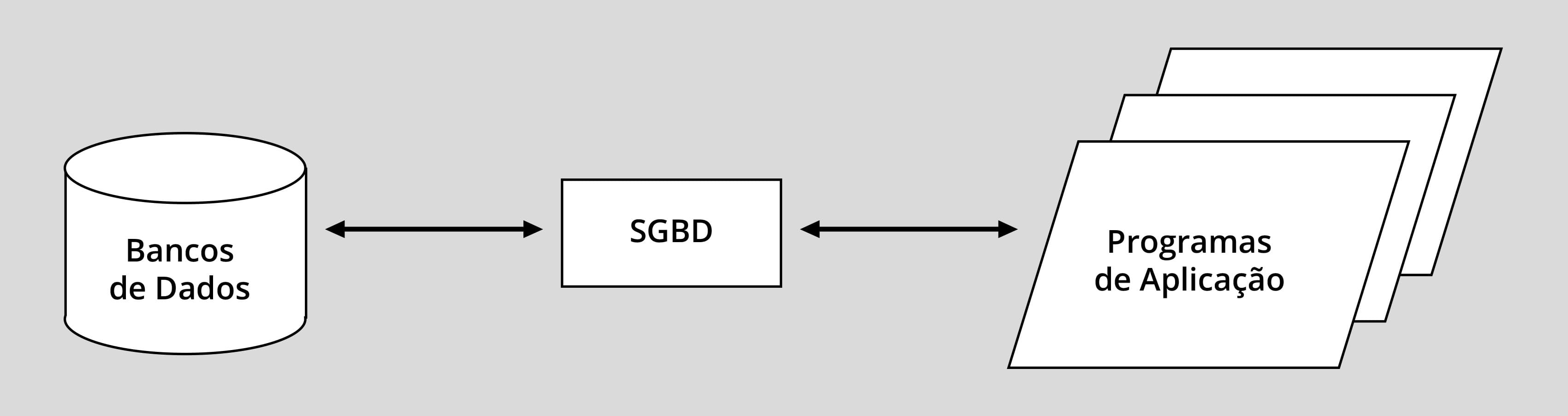
Em outras palavras, ocorreu uma modularização do sistema de informação, com a distribuição de responsabilidades entre os programas de aplicação e o SGBD. Os programas de aplicação passaram a se ocupar exclusivamente das funcionalidades da aplicação propriamente dita, deixando as tarefas de acesso e manipulação dos dados armazenados em disco para o SGBD, um software tipicamente auxiliar, de bastidores ou, como se costuma dizer no jargão do mercado, um serviço de back end.
Atenção
Perceba a diferença entre o sistema de banco de dados (SBD) e o sistema de gerência de banco de dados (SGBD), pois o primeiro é mais amplo, englobando o SGBD, os próprios programas de aplicação e os bancos de dados manipulados por eles.
Neste ponto, cabe um questionamento importante, cada vez mais válido em face dos avanços das tecnologias de hardware de memória, tanto de memória principal (RAM) quanto de memória secundária (discos magnéticos ou hard disk drives (HDD) e de semicondutores ou solid state drives (SSD)).
A questão é: qual dos três modelos de sistemas é o mais eficiente para uma aplicação com o mesmo volume de dados, ou seja, o modelo monolítico com dados junto dos programas; o modelo com sistemas de arquivos; ou o modelo com sistemas de bancos de dados?
Adiaremos a resposta a essa questão para o final deste módulo.
Estágio atual dos sistemas de informação (na Web)
Antes de discorrer sobre o histórico dos SBDs, vale completar a evolução dos sistemas de informação até os dias atuais, fortemente influenciada pela revolução tecnológica causada pela World Wide Web no final do século XX.
Com a popularização da interface Web no desenvolvimento das aplicações, surgiram novas linguagens de programação e novas formas de armazenamento e acesso a dados em fontes com diferentes formatos. Assim, o SGBD das aplicações tradicionais pode ser considerado atualmente como um gênero de software básico, com papel intermediário, que denominamos na figura a seguir de middleware, em que se incluem servidores de aplicações das diferentes linguagens e ambientes de desenvolvimento Web.
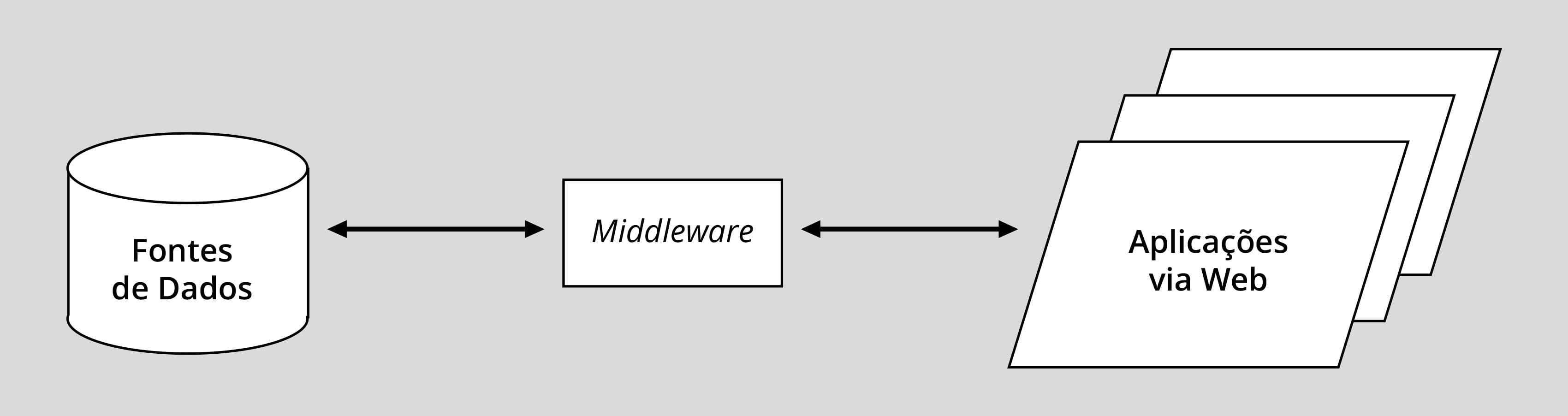
Essa figura resume o atual estágio dos sistemas de informação na Web, em que as fontes de dados não se restringem a dados estruturados, como em bancos de dados tradicionais, admitindo volumes gigantescos em diversos formatos, localizações e velocidade de produção, características marcantes do conceito de Big Data. Igualmente, as aplicações via Web são desenvolvidas em uma diversidade de plataformas digitais, de smartphones a supercomputadores, que têm em comum a conexão com a internet e, em consequência, a computação em nuvem (Cloud Computing).
Evolução dos sistemas de banco de dados
Bancos de dados navegacionais
Há uma controvérsia sobre qual foi o primeiro SGBD implementado e utilizado comercialmente na década de 1960. Sabe-se que duas iniciativas independentes ocorreram paralelamente, resultando em dois produtos comerciais:
Criado por Charles Bachman (1924-2017) no âmbito de um comitê que padronizou a linguagem COBOL (CODASYL, de Committee on Data Systems Languages).
Criado pela IBM na esteira do sucesso da invenção do disco magnético anos antes.
O IDS e o IMS tinham em comum a característica de que os dados eram acessados por meio de programas que “navegam” de registro em registro pela estrutura dos dados armazenados em disco. Por causa dessa característica, atualmente aqueles SGBDs e outros que seguiram a mesma abordagem são denominados de navegacionais.
Observe a diferença entre eles:
IDS
Usava a estrutura de dados de grafos ou redes, daí a denominação de network databases.
IMS
Adotava a estrutura de dados de árvores, que é um tipo de grafo mais restrito do que as redes, baseado em hierarquias, originando a denominação hierarchical databases.
Vários SGBDs foram implementados com variantes desses modelos de banco de dados, como o DMS (Data Management System) e o IDMS (Integrated Database Management System). Vale relembrar que muitos sistemas de informação legados daquela época ainda utilizam esses SGBDs navegacionais, a exemplo da demanda por programadores COBOL em meio à pandemia de COVID-19.
O modelo relacional de banco de dados

A grande revolução na história dos bancos de dados ocorreu na virada das décadas de 1960 e 1970, com a publicação do artigo seminal do matemático pesquisador da IBM, Edgar Codd, intitulado A Relational Model of Data for Large Shared Data Banks, que introduziu o modelo relacional de banco de dados.
O artigo de Codd, uma das obras mais citadas na comunidade da computação em todos os tempos, foi o marco do chamado modelo relacional de banco de dados, cuja estrutura de dados, diferentemente dos grafos dos bancos de dados navegacionais, é uma função matemática denominada relação.
Edgar Codd
Edgar Frank Codd (1923-2003) foi um cientista da computação e matemático americano que inventou o modelo de dados relacionais, que levou à criação do banco de dados relacional, um método padrão de recuperação e armazenamento de dados do computador.
Fonte: Encyclopædia Britannica.Codd criou uma Álgebra Relacional e um Cálculo Relacional, nos quais baseou toda a teoria matemática das relações em que fundamentou o modelo relacional. Apesar da base teórica do modelo, a estrutura de dados subjacente tem o mérito de ser muito simples, pois uma relação nada mais é do que uma tabela formada por colunas e linhas, em cujas células estão armazenados os dados, conceito compreensível pelo senso comum de qualquer leigo em Matemática ou computação, como podemos ver a seguir.
| Linhas/Colunas | Nome | Data de nascimento | Sexo | Departamento |
|---|---|---|---|---|
| Linha 1 | Jorge | 15/01/1999 | Masculino | Produção |
| Linha 2 | Ana | 05/07/1980 | Feminino | Recursos Humanos |
| Linha 3 | Joana | 10/09/1990 | Feminino | Pesquisa |
A solidez da fundamentação matemática do modelo relacional disparou uma série de iniciativas de implementação em empresas, como a própria IBM, e no meio acadêmico, principalmente nas universidades do estado da Califórnia, onde se localizava o centro de pesquisas da IBM. A partir de então, a IBM patrocinou o projeto System R (de Relational), enquanto a Universidade da Califórnia em Berkeley (UCB) deu início à implementação acadêmica de um SGBD relacional denominado de Ingres (Interactive Graphics Retrieval System).

Principais SGBDs relacionais
O projeto System R deu origem ao SGBD comercial da IBM, inicialmente denominado SQL/DS (Structured Query Language/Data System), depois renomeado de DB2, atualmente um dos líderes no mercado de bancos de dados corporativos, com versões em diferentes plataformas de hardware/software e na nuvem.
Saiba mais
A linguagem SQL, criada pela IBM como uma linguagem de consulta e manipulação de dados dos bancos de dados relacionais, passou a ser conhecida como sinônimo de SGBD relacional, chegando a ser confundida com produtos que levam a sigla em seu nome.
No âmbito comercial, também despontou, como decorrência do sucesso do modelo relacional, o desenvolvimento de um SGBD pela empresa inicialmente denominada Software Development Laboratories (SDL), depois renomeada Relational Software Inc. (RSI) e, finalmente, Oracle Corporation, nome pelo qual é atualmente reconhecido como o SGBD líder do mercado global de banco de dados.


Em 2010, com a aquisição da Sun Microsystems, uma grande empresa de hardware tradicionalmente incentivadora de projetos de software livre, a Oracle incorporou entre seus produtos o MySQL, um SGBD relacional de reconhecida liderança na comunidade de desenvolvimento de sistemas para a Web. O SGBD MySQL, associado ao sistema operacional Linux, ao servidor Web Apache e à linguagem de programação PHP, formou o quarteto de software conhecido pela sigla LAMP, de grande sucesso no desenvolvimento de aplicações Web até os dias atuais.
Na frente acadêmica, o projeto Ingres, da UCB (Universidade da Califórnia, Berkeley) deu origem a versões comunitárias mediante licença livre da própria universidade junto com seu sistema operacional Unix, denominado BSD (Berkeley Software Distribution). O projeto acadêmico originou um produto comercial de mesmo nome, Ingres DBMS, que concorreu diretamente com o Oracle e o SQL/DS nos primórdios dos SGBDs relacionais.
O esforço de desenvolvimento do Ingres envolveu muitos pesquisadores, professores e estudantes, os quais acabaram levando o seu código livre em linguagem C para implementação em outros produtos comerciais, notadamente o SGBD Sybase que, na década de 1990, associou-se à Microsoft, dando origem ao SQL Server, atualmente um dos líderes no mercado de bancos de dados relacionais.


A continuidade do projeto Ingres deu frutos também na área acadêmica com a evolução para um modelo de dados além do relacional, estendido com conceitos da programação orientada a objetos, denominado Postgres (de Post Ingres).
Saiba mais
Após a incorporação da linguagem SQL na década de 1990, o Postgres foi rebatizado como PostgreSQL, atualmente reconhecido como o mais avançado SGBD open source do mundo. Para saber mais sobre o PostgreSQL, não deixe de verificar a indicação feita no Explore+ ao fim deste tema.
O PostgreSQL e o MySQL são os SGBDs mais utilizados no aprendizado dos bancos de dados relacionais pela sua popularidade e pelo fato de disponibilizarem versões com licença e documentação livres.
Outros modelos de SGBDs
No ranking de popularidade dos SGBDs, disponibilizado pelo DB-Engines em seu website, destacam-se, entre os que adotam o modelo relacional: Oracle, MySQL, Microsoft SQL Server, PostgreSQL e IBM DB2.
Cabe observar que esse ranking não trata exclusivamente de SGBDs do modelo relacional de dados. Os próprios SGBDs relacionais, mencionados como líderes de mercado, são classificados no ranking como “multimodelos”, porque implementam funcionalidades que vão além do modelo relacional. Vejamos:
Relacional e multimodelo (documentos, grafos e RDF)
Relacional e multimodelo (documentos)
Relacional e multimodelo (documentos e grafos)
Relacional e multimodelo (documentos)
Relacional e multimodelo (documentos e RDF)
E o que são esses outros modelos de banco de dados, além do relacional?
Não resta dúvida de que o modelo relacional se firmou no mundo corporativo, sendo utilizado na grande maioria dos sistemas de informação empresariais pela sua popularidade e robustez dos produtos disponíveis ao longo de décadas de desenvolvimento, bem como pela padronização e pelo uso da linguagem de consulta e manipulação de dados SQL.
Entretanto, existem aplicações em sistemas de informação que requerem muito mais recursos de armazenamento e manipulação de dados do que as tabelas do modelo relacional, em especial aplicações Web e de cunho científico que processam grandes quantidades de dados em formatos diversos, com as atuais tendências como Big Data, Internet of Things e Data Science.
Assim, vários modelos de banco de dados não relacionais vêm surgindo no mercado, sendo denominados de NoSQL, termo traduzido como “Não SQL” ou “Não somente SQL” (de Not Only SQL).
São, de fato, bancos de dados que não adotam o modelo relacional de dados e, portanto, não usam a linguagem SQL, embora alguns possuam implementações do comando SELECT da SQL para fins de compatibilidade de linguagem de consulta com os bancos de dados relacionais.
O estudo de bancos de dados NoSQL está fora do escopo deste tema, constituindo-se em um tema à parte pela diversidade dos seus conceitos e de suas tecnologias.

É importante conhecer a importância dessa tendência dos SGBDs, como demonstra o site DB-Engines Ranking, que apresenta mais de uma dúzia de modelos de bancos de dados NoSQL com seus principais produtos, muitos deles multimodelos.
Saiba mais
Confira a lista de multimodelos
- Chave-Valor: Redis, Amazon DynamoDB, Microsoft Azure CosmosDB.
- Documentos: MongoDB, Amazon DynamoDB, Microsoft Azure CosmosDB.
- Séries temporais: InfluxDB, KDB+, Prometheus.
- Grafos: Neo4J, Microsoft Azure CosmosDB, ArangoDB.
- Orientado a objetos: InterSystems Caché. Versant Object Database, ObjectStore.
- Motores de busca: Elasticsearch, Splunk, Solr.
- RDF (Resource Description Framework): Marklogic, Apache Jena, Virtuoso.
- Colunar: Cassandra, HBase, Microsoft Azure CosmosDB.
- Multivalores: Adabas, UniData/UniVerse, jBASE.
- XML nativo: Marklogic, Oracle Berkeley DB, Virtuoso.
- Eventos: Event Store, IBM DB2 Event Store, NEventStore.
- Conteúdos: JackRabbit, ModeShape.
- Navegacional: IMS, IDMS.
Comentário
O modelo navegacional é exatamente aquele dos primórdios dos sistemas de banco de dados, da década de 1960, antes do advento do modelo relacional, cujos produtos ainda continuam sendo utilizados, principalmente em sistemas de informação legados daquela época.
Para fechar o módulo, neste vídeo o professor Sidney Ventury aprofundará o conteúdo falando um pouco mais sobre as vantagens que o Banco de Dados trouxe em relação ao antigo sistema de arquivos.
O modelo relacional de banco de dados.
Verificando o aprendizado
ATENÇÃO!
Para desbloquear o próximo módulo, é necessário que você responda corretamente a uma das seguintes questões:
O conteúdo ainda não acabou.
Clique aqui e retorne para saber como desbloquear.
MÓDULO 2
Identificar as características dos sistemas de banco de dados (SBD)
Diferenças entre sistema de arquivos e sistema de banco de dados
No módulo anterior, verificamos que uma característica primordial que distingue os sistemas de banco de dados dos sistemas baseados de arquivos é a independência dos dados em relação a programas. Essa, na verdade, é apenas uma espécie da característica dos sistemas de banco de dados denominada independência de dados.
O conceito de independência de dados deriva da arquitetura de três esquemas do banco de dados que separa as aplicações dos usuários finais do banco de dados físico armazenado.
A figura a seguir é uma adaptação da arquitetura ANSI/SPARC, que considera três níveis de esquemas: o nível externo, que contém o esquema conceitual externo, integrando as diferentes visões dos usuários das aplicações; o nível conceitual, o qual contém o esquema conceitual lógico ou de implementação, descrevendo a estrutura lógica do banco de dados; e o nível interno, que contém o esquema interno ou físico do banco de dados armazenado em disco.
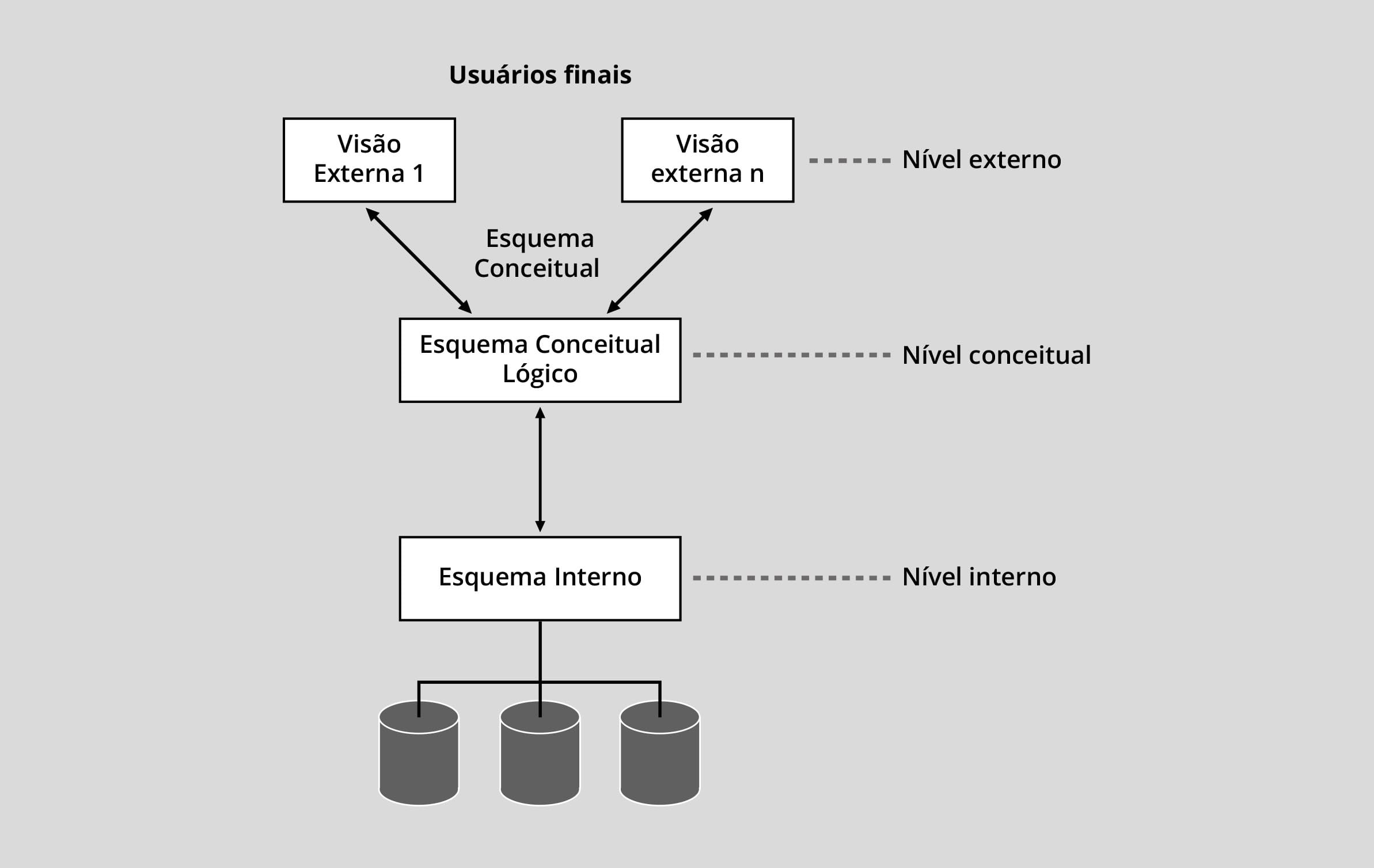
Essa arquitetura serve para definir dois tipos de independência de dados, além da independência entre dados e programas já estudada:
Independência lógica de dados
Consiste na capacidade de se alterar o esquema conceitual lógico, por exemplo, acrescentando um item de dado, sem alterar o esquema conceitual externo, isto é, as visões externas dos usuários através dos programas de aplicação.
Independência física de dados
Consiste na capacidade de se alterar o esquema interno, por exemplo, reorganizando os arquivos físicos que armazenam os dados, sem alterar o esquema conceitual lógico e, em consequência, o esquema conceitual externo.
Outras características, entre muitas, que diferenciam os sistemas de bancos de dados dos sistemas de arquivos são descritas a seguir.
Significa que, além dos dados, o SBD contém a descrição completa de suas estruturas e restrições. Como se verá na arquitetura do SGBD, a descrição da estrutura e das restrições de dados, conhecida como metadados, isto é, dados que descrevem dados, é armazenada no catálogo do sistema de banco de dados.
Permite a representação conceitual dos dados por meio de modelos de dados que ocultam detalhes de armazenamento e implementação, os quais não interessam aos diferentes usuários, dando suporte a múltiplas visões lógicas dos dados e à independência de dados.
Permite que múltiplos usuários acessem o banco de dados simultaneamente.
Neste vídeo, o professor Sidney Ventury reforçará pontos importantes como os metadados e a arquitetura de três esquemas.
Os modelos de dados que suportam a abstração de dados e permitem sua independência lógica e física são classificados em modelos físicos, lógicos e conceituais.
Descrevem como os dados são armazenados no computador mediante informações como tipos de arquivos, formatos e ordenação de registros, caminhos de acesso. São as várias formas de estruturas de arquivos que dependem do SGBD e do sistema operacional em que estão instaladas.
São aqueles que representam, de maneira abstrata, a implementação dos bancos de dados, ocultando detalhes de como os dados são armazenados e acessados no disco. O modelo lógico mais tradicional, largamente utilizado na grande maioria dos sistemas de informação organizacionais, é o modelo relacional criado por Edgar Codd, mencionado no módulo anterior. A estrutura de dados do modelo relacional é a tabela (relação matemática) e deve ser estudada em profundidade em tema específico, assim como as implementações de SGBD relacional. Como vimos, há outros modelos lógicos de implementação do banco de dados entre aqueles que atualmente se denominam de modelos não relacionais ou NoSQL.
São aqueles que representam a visão dos dados do ponto de vista do usuário final, no nível de abstração mais próximo do mundo real. Dentre esses, destaca-se o modelo de entidades e relacionamentos, criado pelo pesquisador Peter Chen, em 1976. O chamado modelo ER, segundo o próprio autor, foi criado para prover um melhor entendimento do modelo relacional, de modo a servir como uma etapa inicial no processo de projeto de banco de dados, denominada de modelagem conceitual dos dados.
Vale destacar que a modelagem conceitual de dados realizada com o modelo ER foi incorporada na linguagem UML (Unified Modeling Language), criada no final da década de 1990 para uniformizar a modelagem orientada a objetos sob a forma do modelo de classes, em que as entidades são representadas pelas classes de objetos e os relacionamentos pelas associações entre as classes. Na prática atual do processo de desenvolvimento de sistemas de informação, é comum a utilização do modelo de classes da UML como substituto do modelo ER nas fases iniciais do projeto de banco de dados.
Atenção
Nesse ponto, vale a pena revisitar a definição de banco de dados citada no início do primeiro módulo, complementando-a com as principais características aqui mencionadas, Assim, podemos definir banco de dados como uma coleção autodescritiva de dados relacionados, com significado lógico inerente, que pode ser manipulada concorrentemente por usuários com visões diferentes.
Vantagens e desvantagens da abordagem de banco de dados
A abordagem de SBD possui funcionalidades que conferem vantagens adicionais em relação a sistemas sem banco de dados, além das características que a diferenciam da abordagem de sistemas de arquivos. Algumas dessas funcionalidades do SBD são listadas a seguir e podem ser objeto de estudo em temas sobre implementação e administração de banco de dados.
Previne a possibilidade de inconsistência dos dados, a duplicação de esforço para manter os dados atualizados e o desperdício de espaço de armazenamento. O SGBD permite controlar o trade off entre o armazenamento em um único local no banco de dados versus a redundância forçada para melhorar o desempenho das consultas.
Sendo os SBD multiusuários, realizam controle de concorrência de acesso aos dados compartilhados para garantir as propriedades de atomicidade, consistência, isolamento e durabilidade (propriedades ACID) das transações de banco de dados.
Mecanismos de segurança e autorização, como senhas para usuários e para grupos de usuários; restrição de acesso a partes do banco de dados; proibição de executar certas operações privilegiadas; acesso de usuário restrito apenas a transações autorizadas; proibição de uso de software privilegiado, como o software de administração do SBD.
Provê diferentes linguagens de consulta para usuários casuais; linguagens de programação para programadores de aplicações; interfaces gráficas com formulários (telas) e menus para usuários de aplicações; interfaces para administração do banco de dados; interfaces de linguagem natural.
Permite representar os relacionamentos existentes entre dados no mundo real, mediante mecanismos que dependem do modelo lógico de implementação do SBD.
Previne a violação de restrições como tipo de dado ou domínio de valores admissíveis; unicidade de itens de dados por meio de chaves únicas; integridade referencial entre dados relacionados e restrições derivadas da semântica dos dados. Aqui também o SGBD permite controlar o trade off entre garantir o cumprimento automático das restrições ou deixar a sua especificação para os programas de aplicação.
Em caso de ocorrência de falhas de hardware ou de software, os mecanismos de cópia de segurança (backup) e posterior restauração (recovery) garantem a consistência de estado do banco de dados antes e depois da falha.
É uma característica primordial do SBD e tem como resultado o controle de concorrência das transações.
É responsabilidade do SGBD garantir as propriedades das transações, conhecidas pela sigla ACID, relaxando-as quando necessário para manter o desempenho sob seu controle e para não violar a integridade do banco de dados.

Atomicidade (Atomicity)
Cada transação é tratada como uma unidade composta de uma sequência de operações, de modo que deve executar completamente com sucesso ou falhar completamente.

Consistência (Consistency)
Uma transação só pode levar o banco de dados de um estado válido para outro, de acordo com suas regras de integridade.

Isolamento (Isolation)
Cada transação é isolada das demais, isto é, essa propriedade assegura que transações executadas concorrentemente levem o banco de dados ao mesmo estado que chegaria se as transações fossem executadas sequencialmente.

Durabilidade (Durability)
Uma vez que a transação é aceita (committed), o que significa que seu resultado foi gravado em memória não volátil, esse resultado permanecerá válido mesmo em caso de falhas do sistema.


Vantagens
As vantagens decorrentes dessas funcionalidades do SBD são várias: potencial para o estabelecimento de padrões de uso dos dados na organização; redução do tempo de desenvolvimento de aplicações; flexibilidade na manutenção dos dados; disponibilidade dos dados atualizados no âmbito de toda a organização; economia de escala, entre outras.

Desvantagens
Agora, vejamos as desvantagens da abordagem de banco de dados. Como já foi observado, a presença do SGBD como um software intermediário entre as aplicações e os dados armazenados provoca uma sobrecarga no desempenho do sistema como um todo. Além disso, há de se levar em conta o custo e o esforço adicional na capacitação e no oferecimento de funcionalidades sofisticadas como as já citadas anteriormente.
Assim, pode-se dizer que é preferível não usar a abordagem de SBD em algumas aplicações, tais como:
- Aplicações muito simples com dados estáticos e bem definidos, que se espera que não sejam alterados (exemplo: censo demográfico);
- Aplicações de tempo real com requisitos rígidos os quais não possam ser atendidos com o overhead causado pelo SGBD (exemplo: controle de tráfego aéreo);
- Sistemas embarcados, com poucos dados e com requisitos estritos de tempo real (exemplo: piloto automático);
- Sistemas monousuários de uso sem concorrência, típicos de aplicações em desktop (exemplo: prontuário eletrônico de um único consultório médico).

Poderiam ser enquadradas nessa lista as aplicações que requerem dados volumosos com dinâmica não processável por SGBDs tradicionais, como a Internet das Coisas (IoT, de Internet of Things), porém, o advento de bancos de dados NoSQL, com modelos de dados específicos para tratamento de Big Data, busca a atender a esses tipos de aplicações incompatíveis com os modelos tradicionais de SGBD.
Funcionalidades e propriedades das transações do Sistema de Banco De Dados.
Papéis em sistemas de bancos de dados
A figura a seguir mostra as camadas de um sistema de computação desde o hardware, onde são armazenados os arquivos com programas e dados, até as aplicações disponíveis aos usuários finais, que podem ser desenvolvidas com ou sem a utilização de um SGBD. Na ilustração, podemos ver também a existência de diferentes papéis de usuários ao longo das camadas de software.
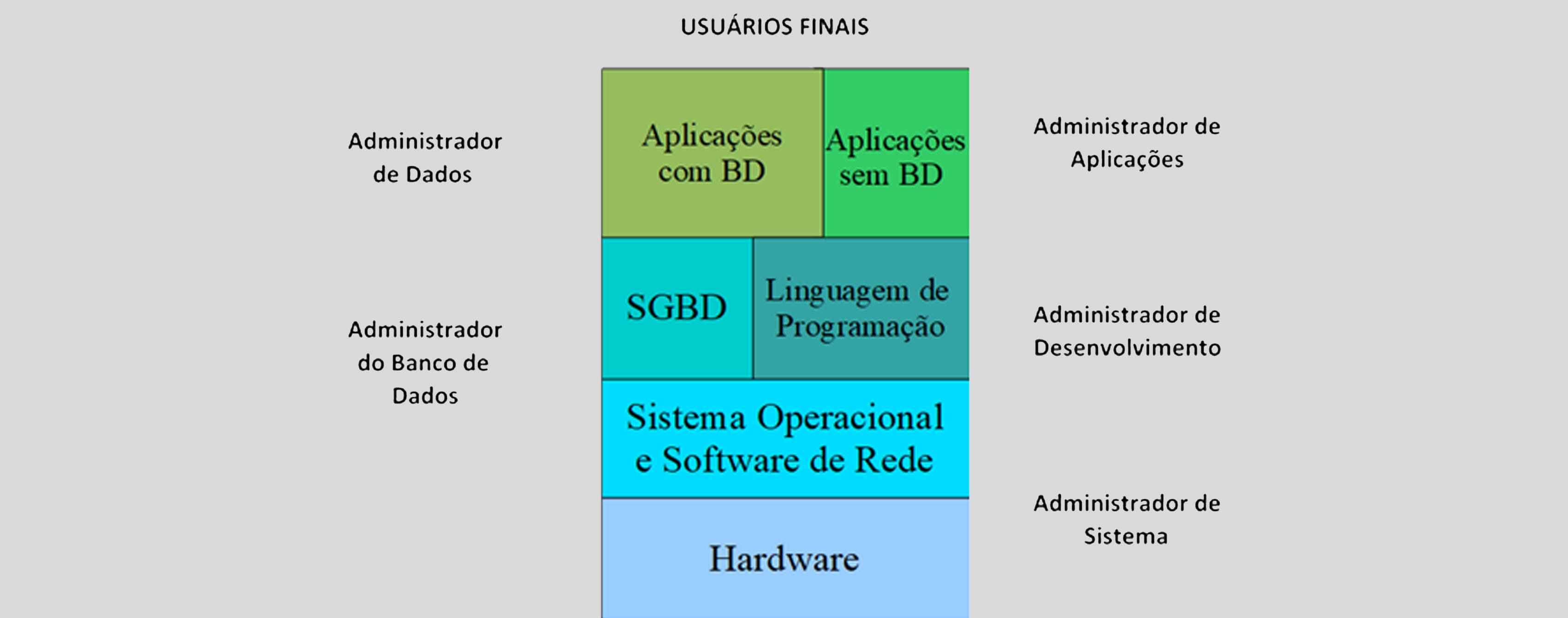
Em um sistema de computação corporativo de grandes organizações, é possível separar os diferentes papéis desempenhados como mostra a figura.
Beneficiários dos sistemas que rodam no sistema de computação, seja por aplicações desenvolvidas com a abordagem de banco de dados ou não.
Função técnico-gerencial responsável pela manutenção dos sistemas de aplicação e pelo suporte aos seus usuários, podendo ser exercida por vários administradores. Exemplo: administrador do sistema integrado de gestão empresarial, conhecido pela sigla ERP (Enterprise Resource Planning).
Função técnica que pode ser desdobrada em equipes de desenvolvimento do sistema de aplicação, dependendo do porte e da complexidade do sistema, que se utilizam das ferramentas disponíveis no ambiente de desenvolvimento de sistemas.
Função gerencial responsável pelo ambiente de dados da organização, que define políticas e responsabilidades sobre os recursos de dados, assim como as regras do negócio e os padrões de dados a serem seguidos no desenvolvimento.
Função técnica responsável pela criação e manutenção dos bancos de dados no SGBD, dando suporte às equipes de desenvolvimento no tocante aos objetos dos bancos de dados.
Responsável por manter no ar o sistema de computação como um todo, com foco no hardware e no sistema operacional, bem como nas interfaces deste com os demais softwares instalados.
Cabe observar que nem todos os papéis de administração podem ser exercidos por uma única pessoa, mas uma pessoa pode exercer mais de um papel. A distribuição desses papéis por pessoas e equipes dependerá do porte da organização e do sistema de computação, variando desde uma única pessoa exercendo todos os papéis de administração até todo um departamento de TI encarregado da administração e do suporte aos diversos sistemas em operação.
Verificando o aprendizado
ATENÇÃO!
Para desbloquear o próximo módulo, é necessário que você responda corretamente a uma das seguintes questões:
O conteúdo ainda não acabou.
Clique aqui e retorne para saber como desbloquear.
MÓDULO 3
Descrever a arquitetura dos sistemas de gerência de banco de dados (SGBD)
Componentes de um sistema de banco de dados
A figura a seguir mostra uma visão simples do ambiente de banco de dados, compreendendo programas de aplicação ou consultas de usuários que acessam os dados e metadados armazenados em disco através do SGBD. Este, por sua vez, compõe-se, simplificadamente, de um software para processar consultas e programas e outro para acessar os dados e metadados armazenados.
Nota-se, na figura, que não se confundem o SBD e o SGBD, visto que este é um componente daquele que engloba também os programas e as consultas, bem como os dados e metadados armazenados.
A fronteira do SBD engloba os programas que implementam as aplicações, bem como as consultas provenientes de usuários com acesso a linguagens e interfaces de consulta. O SGBD é o software intermediário, uma caixa preta a ser aberta no próximo módulo. A fronteira do SBD envolve os metadados armazenados no catálogo (às vezes chamado de dicionário de dados) e o próprio conteúdo armazenado no banco de dados.
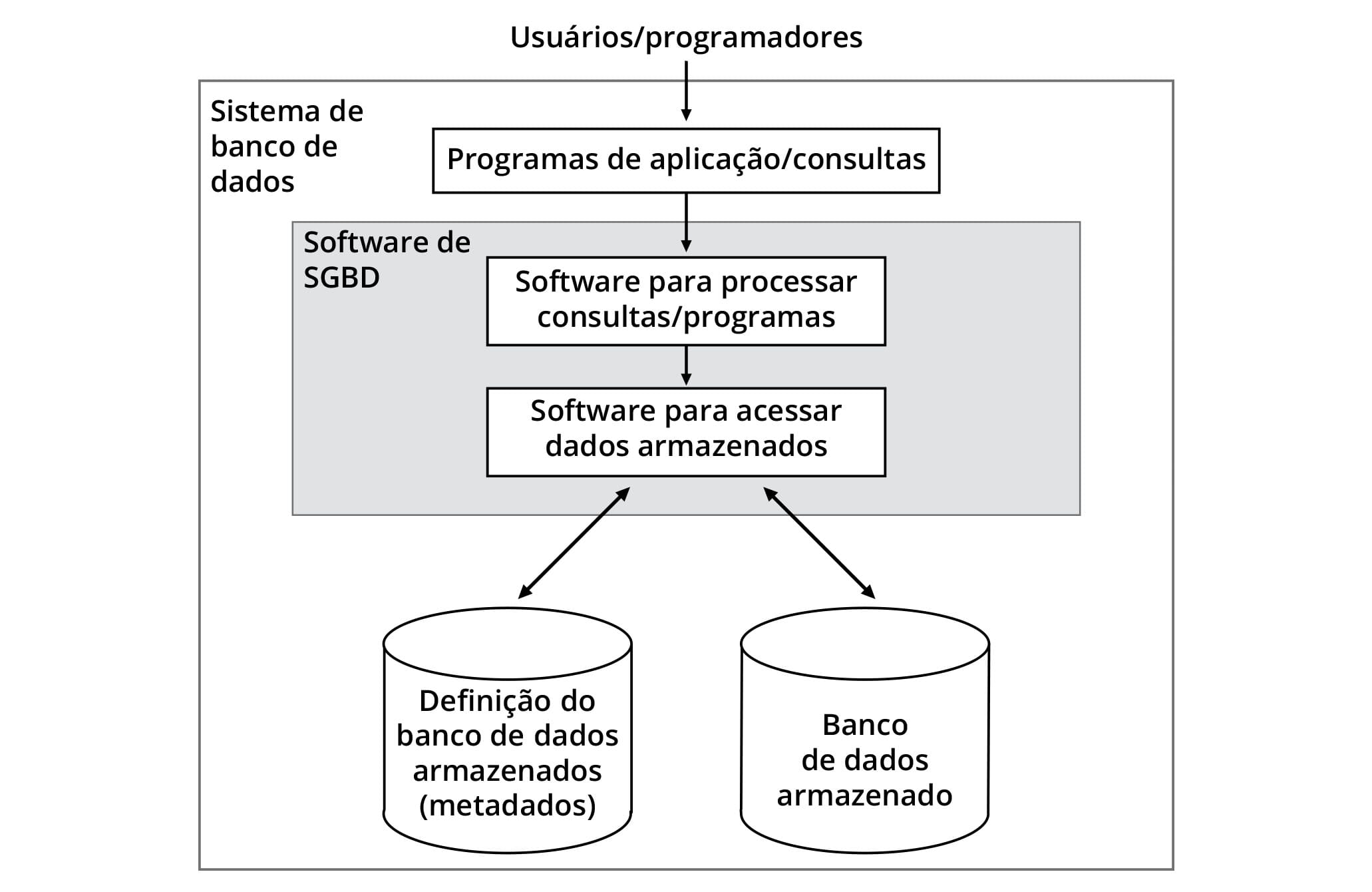
Costuma-se definir metadados como o esquema do banco de dados, estruturado de acordo com o modelo lógico de implementação. Assim, modelar um banco de dados consoante ao modelo lógico de implementação equivale a esquematizar o banco de dados conforme os construtores desse modelo. Por exemplo, no modelo relacional, o esquema é composto por tabelas e suas colunas. Cada comando de definição de dados, criando, alterando ou removendo uma tabela, provoca uma mudança no esquema do banco de dados.
Por outro lado, chama-se de estado ou instância o conteúdo do banco de dados armazenado em um momento. Cada manipulação no banco de dados mediante comandos de inserção, atualização ou remoção de dados provoca uma mudança de estado, gerando uma nova instância do banco de dados.
Como vimos, o termo banco de dados é correntemente usado com o sentido do original, em inglês, database, cuja origem, segundo o Oxford English Dictionary, remonta a 1962 num relatório de uma empresa na Califórnia. Raras são as referências ao termo data bank como, por exemplo, no mencionado artigo de Edgar Codd sobre o modelo relacional (CODD, 1970).
Em espanhol, usa-se base de datos, no francês base de données, enquanto em alemão se diz Datenbank, e em italiano banca dati.
Em português, existem os dois termos, sendo banco de dados usado no sentido geral do ambiente que engloba o sistema, como na figura anterior, enquanto base de dados tem o sentido mais restrito do conteúdo do banco, isto é, corresponde ao estado ou à instância do banco de dados. Por exemplo, costuma-se referir à base de dados da Receita Federal como o conjunto de dados armazenados sobre os contribuintes e não como o sistema que gerencia os dados.
Módulos de um sistema de gerência de banco de dados
A figura a seguir ilustra, em detalhes, os diversos módulos que compõem um SGBD, sendo a parte superior correspondente ao processamento das consultas e aplicações, e a parte inferior ao acesso a metadados e dados armazenados (a base de dados).
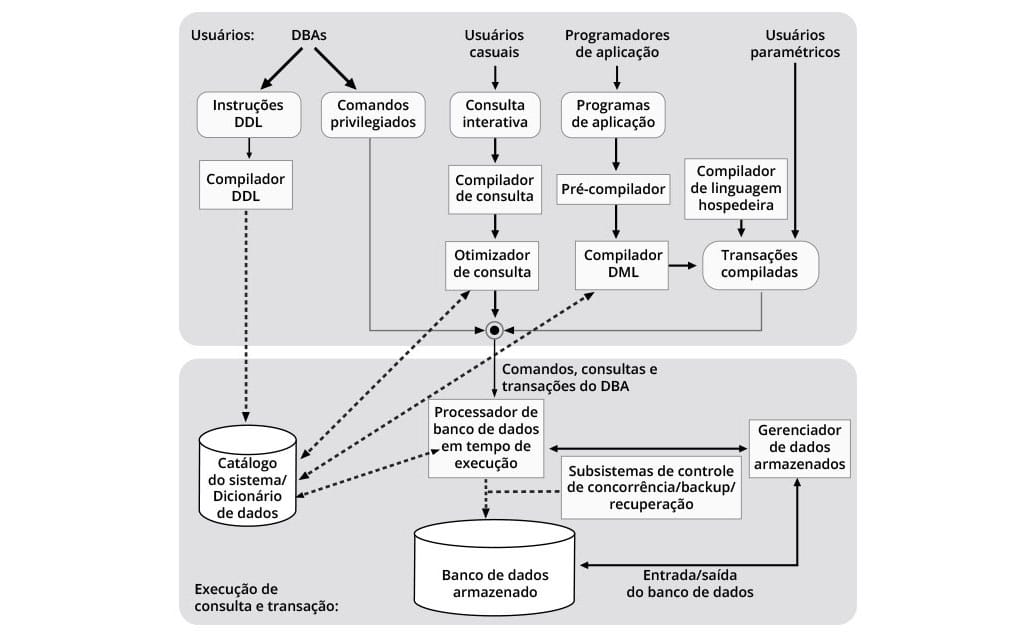
Vamos conferir a descrição desses módulos.
Da esquerda para a direita, vemos os usuários, começando com os administradores de banco de dados (ABD, do inglês DBA – Database Administrator).
O ABD usa comandos da linguagem de definição de dados (LDD, do inglês DDL – Data Definition Language) para criar, alterar ou remover objetos do banco de dados (comandos CREATE, ALTER, DROP no padrão SQL), os quais ficam armazenados no catálogo do sistema, que contém os metadados.
O ABD também possui privilégio para executar comandos de controle de dados, conhecidos por alguns autores como linguagem de controle de dados (LCD, do inglês DCL – Data Control Language), para conceder e revogar permissões de acesso aos dados (comandos GRANT e REVOKE no padrão SQL), entre outros. Note que o destino desses comandos privilegiados é um nó central do SGBD, por onde passam todos os comandos destinados ao processador de banco de dados em tempo de execução, denominado de processador de runtime ou runtime engine.
Seguindo para a direita, vemos os usuários casuais, os quais fazem consultas interativas através de uma interface para consultas ad hoc, ou seja, consultas não programadas previamente. As consultas são feitas tipicamente com o comando SELECT no padrão SQL do modelo relacional e provido de modo similar em outros modelos de implementação de banco de dados. Esses comandos são compilados por um compilador da linguagem de consulta e passam por um otimizador de consulta antes de chegar ao nó central do SGBD.
Mais à direita, aparecem os programadores de aplicações que escrevem os programas em uma linguagem de programação hospedeira, como por exemplo, Java, PHP ou Python, nos quais estão embutidos comandos de consulta (SELECT), inserção, atualização e exclusão de dados em uma linguagem de manipulação de dados (LMD, do inglês DML – Data Manipulation Language).
No padrão SQL, esses comandos são, respectivamente, INSERT, UPDATE e DELETE. Note que eles manipulam dados, diferentemente dos comandos da linguagem de definição de dados (CREATE, ALTER, DROP), que manipulam metadados.
Os programas de aplicação, portanto, possuem comandos híbridos, da linguagem hospedeira e da linguagem de consulta e manipulação de dados.
Os programas de aplicação são processados, inicialmente, por um pré-compilador, responsável por separar os comandos e os repassar para os compiladores das respectivas linguagens.
Cabe a esses compiladores produzir o código das aplicações sob a forma de transações executáveis, que ficam à disposição dos usuários paramétricos.
Os usuários paramétricos são assim chamados porque interagem com o sistema através de parâmetros passados em interfaces apropriadas. Por exemplo, um agente de viagens faz uma reserva de passagem aérea passando ao sistema os dados do passageiro, data e hora da viagem, número do voo, número do assento e outros parâmetros necessários para efetivar a reserva.
Uma vez executadas as transações compiladas, assim como os demais comandos provenientes de usuários ou aplicações, são passadas ao nó central do SGBD para posterior processamento do processador de runtime.
Atenção! Antes de prosseguir na parte de baixo da figura, note que alguns processos da parte de cima, como o otimizador de consulta e o compilador da LMD, estão ligados ao catálogo por linhas tracejadas, que denotam fluxos de controle, enquanto as linhas cheias representam fluxos de dados, além de controle. Isso é necessário porque as referências a objetos do banco de dados existentes no catálogo devem ser consistentes com os objetos, criados e mantidos pelo ABD mediante comandos da LDD.
Prosseguindo para a parte do processamento do acesso aos dados armazenados, observamos que o processador de runtime é o coração do SGBD. De fato, o diferencial dos produtos de SGBD reside na eficiência e na funcionalidade desse processador, segredo industrial em muitos dos SGBDs proprietários, a ponto de exigir rigorosos termos de confidencialidade das pessoas que têm acesso ao seu código.
O processador de runtime também precisa acessar e, por vezes, modificar o catálogo, dependendo da natureza dos comandos, das consultas ou transações que estiver processando. Como mostra a figura, ele acessa a base de dados diretamente, sob controle de subsistemas de controle de concorrência, backup e recovery. Quando precisa realizar operações de entrada e saída (gravação e leitura) na base de dados, o processador de runtime se vale de um gerenciador de dados armazenados.
A descrição dada, embora simplificada, denota a complexidade de um SGBD, software que evoluiu desde a década de 1960 a ponto de se tornar um recurso robusto, eficiente e indispensável para a maioria das organizações privadas ou públicas, principalmente com base no modelo relacional de banco de dados.
Existe uma grande quantidade de SGBDs disponíveis no mercado, como mostrou o DB-Engines Ranking, ao listar mais de 300 SGBDs, sendo cerca de 130 deles do modelo relacional.
Saiba mais
A excelente entrada na Wikipédia, intitulada Comparison of relational database management systems, faz uma comparação de diversas características de SGBDs relacionais, contendo informações detalhadas sobre mais de 60 produtos.
Neste vídeo, o professor Sidney Ventury abordará pontos importantes como runtime, transações compiladas, entre outros.
Um exemplo de SGBD relacional: PostgreSQL
Como vimos anteriormente na evolução histórica dos SGBDs, o PostgreSQL originou-se do projeto Ingres da Universidade da Califórnia em Berkeley, na década de 1970, tendo sido sucessivamente renomeado de Postgres (Post Ingres), depois Postgres 95 e, finalmente, PostgreSQL.
Embora fossem implementações do modelo relacional proposto por Edgard Codd (CODD, 1970), o Ingres e o Postgres originalmente usavam uma linguagem diferente da SQL, adotada pela IBM, conhecida como QueL (Query Language). Por muitos anos, a QueL persistiu nesses SGBDs em concorrência direta com a SQL da IBM, até que o ANSI (American National Standard Institute) e depois a ISO (International Standard Organization) reconheceram a SQL como a linguagem padrão para o banco de dados relacional. A partir de então, a SQL foi implementada no Postgres, passando a ser chamada de PostgreSQL.
O PostgreSQL, além de ser reconhecido como the world's most advanced open source relational database, possui uma completa documentação igualmente reconhecida como referência global para os conceitos de SGBD relacional. Não é sem razão que o PostgreSQL, por ser open source e ter licença livre, é vastamente utilizado no ensino de banco de dados, além de ser adotado comercialmente em grandes organizações ao redor do mundo.
O PostgreSQL é um típico SGBD relacional-objeto, isto é, um SGBD cuja estrutura de dados básica é a relação (tabela), porém contempla extensões de tipos de dados e características próprias da orientação a objetos. Assim, possui suporte em grande parte ao padrão SQL e implementa extensões úteis como: consultas complexas, gatilhos (triggers), visões materializadas atualizáveis, controle de concorrência multiversionado. Além disso, pode ser estendido de muitas formas, por exemplo, gerando novos tipos de dados, funções genéricas e agregadas, operadores, métodos de indexação e linguagens procedurais.
Em jargão de sistemas, o PostgreSQL usa um modelo de computação cliente/servidor, assim como a maioria dos SGBDs relacionais empresariais. Uma sessão PostgreSQL consiste dos seguintes processos cooperativos (programas):
Back end
Um processo servidor (back end), responsável por gerenciar os arquivos do banco de dados, aceitar conexões por aplicações clientes e executar ações sobre o SBD em nome dos clientes. O programa servidor é chamado postgres.
Front end
As aplicações clientes de usuários (front end) que desejam executar operações no banco de dados. Aplicações clientes podem ser diversas em natureza, como uma ferramenta orientada a texto, uma aplicação gráfica, um servidor Web que acessa o banco de dados para exibir páginas Web, ou uma ferramenta especializada de manutenção. Algumas aplicações clientes são fornecidas com a distribuição PostgreSQL (psql, pgadmin).

O PostgreSQL roda em todos os sistemas operacionais importantes, incluindo Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) e Windows. Possui todas as propriedades ACID das transações (atomicidade, consistência, isolamento e durabilidade) e tem completo suporte para chaves estrangeiras, junções, visões, funções, triggers, e procedimentos armazenados em múltiplas linguagens de programação, incluindo Java, Perl, Python, Ruby, Tcl, C/C++, e sua própria PL/pgSQL, similar à PL/SQL do Oracle.
Como banco de dados de classe empresarial, PostgreSQL possui características sofisticadas como controle de concorrência multiversão (Multi Version Concurrency Control), recuperação "point in time" (PiTR – Point in Time Recovery), tablespaces, replicação assíncrona, transações aninhadas (savepoints), online/hot backups, um sofisticado planejador/otimizador de consultas, e write ahead logging (WAL) para tolerância a falhas.
O PostgreSQL é altamente escalável tanto na quantidade de dados que pode gerenciar como no número de usuários concorrentes que pode acomodar. Existem sistemas PostgreSQL em ambientes de produção que gerenciam centenas de usuários simultâneos com dezenas de terabytes de dados armazenados.
Além de possuir um catálogo de sistema totalmente relacional, capaz de suportar múltiplos schemas por database, o catálogo do PostgreSQL é também acessível através do Information Schema, um conjunto de visões de metadados definido no padrão SQL.

Atenção
PostgreSQL suporta índices compostos, parciais e funcionais que podem usar seus métodos de armazenamento B-tree, R-tree, hash ou GiST. Este último é um sofisticado framework que serve de base para muitos projetos públicos que usam PostgreSQL, como o OpenFTS (Open Source Full Text Search engine), que provê indexação online de dados e ranking de relevância para pesquisa em bancos de dados, e o PostGIS, um projeto que adiciona suporte para objetos geográficos, permitindo seu uso como banco de dados espacial para Sistemas Geográficos de Informação.
Outras características avançadas do PostgreSQL incluem herança de tabelas, sistema de regras e eventos de banco de dados.
Coloca um "sabor" orientado a objeto na criação de tabelas, permitindo a projetistas de banco de dados derivar novas tabelas de outras tabelas, tratando-as como classe base. Esse esquema suporta tanto herança simples como múltipla.
Também chamado de sistema de reescrita de consultas, permite ao projetista de banco de dados criar regras que identificam operações específicas para uma dada tabela ou visão e dinamicamente transformá-las em operações alternativas quando são processadas (cláusula INSTEAD OF).
É um sistema de comunicação interprocessos em que mensagens e eventos podem ser transmitidos entre clientes usando os comandos LISTEN e NOTIFY, permitindo tanto comunicação simples peer to peer como avançadas coordenações entre eventos de banco de dados. Clientes PostgreSQL podem monitorar eventos de banco de dados, como atualizações, inserções e exclusões em tabelas, enquanto eles acontecem.
Atenção
O código fonte do PostgreSQL é disponível sob a licença open source BSD. Essa licença dá a liberdade de usar, modificar e distribuir o PostgreSQL da forma que se desejar, com código aberto ou fechado. Quaisquer modificações, melhoramentos ou mudanças que você faça serão seus para fazer o que quiser. Por isso, o PostgreSQL não é somente um poderoso SGBD capaz de rodar o negócio da empresa. Também é uma plataforma de desenvolvimento sobre a qual se pode desenvolver produtos de software in-house que requeiram um suporte adequado a banco de dados.
Com a grande aceitação do PostgreSQL no mercado, desde 2004, um grupo de contribuidores do seu desenvolvimento fundou a empresa Enterprise DB, que fornece uma versão empresarial de mesmo nome, com consideráveis extensões ao PostgreSQL.
UM EXEMPLO DE SGBD RELACIONAL: POSTGRESQL.
Verificando o aprendizado
ATENÇÃO!
Para desbloquear o próximo módulo, é necessário que você responda corretamente a uma das seguintes questões:
O conteúdo ainda não acabou.
Clique aqui e retorne para saber como desbloquear.
Conclusão
Considerações Finais
Este tema abordou uma introdução aos sistemas de banco de dados, resumindo sua evolução histórica desde a invenção do disco magnético, que possibilitou o início da era de processamento de dados por computador.
Foram examinadas as principais características do sistema de banco de dados (SBD), com ênfase naquelas que o diferenciam dos sistemas de arquivos, bem como nas suas funcionalidades, vantagens e desvantagens.
Finalizamos o tema com a descrição da arquitetura de um sistema de gerência de banco de dados (SGBD), componente central do SBD, terminando com um exemplo de SGBD relacional, amplamente utilizado no ensino e no mercado, o PostgreSQL.
Encerraremos este tema aprofundando um pouco mais sobre sistema de banco de dados.
Podcast
CONQUISTAS
Você atingiu os seguintes objetivos:
Reconheceu o histórico dos bancos de dados e suas tecnologias
Identificou as características dos sistemas de banco de dados (SBD)
Descreveu a arquitetura dos sistemas de gerência de banco de dados (SGBD)